DataParsers#
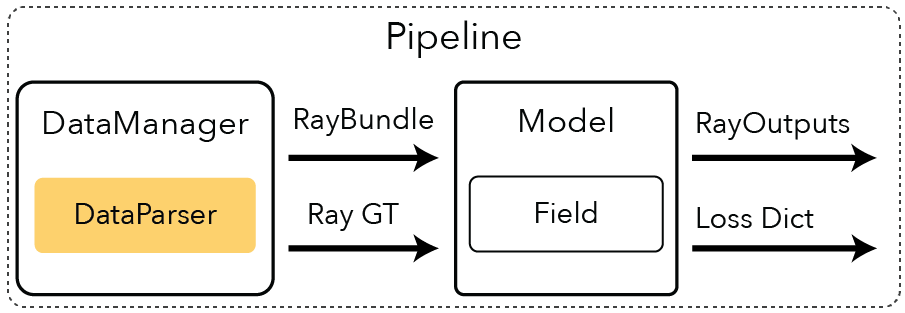
What is a DataParser?#
The dataparser returns DataparserOutputs, which puts all the various datasets into a common format. The DataparserOutputs should be lightweight, containing filenames or other meta information which can later be processed by actual PyTorch Datasets and Dataloaders. The common format makes it easy to add another DataParser. All you have to do is implement the private method _generate_dataparser_outputs shown below.
@dataclass
class DataparserOutputs:
"""Dataparser outputs for the which will be used by the DataManager
for creating RayBundle and RayGT objects."""
image_filenames: List[Path]
"""Filenames for the images."""
cameras: Cameras
"""Camera object storing collection of camera information in dataset."""
alpha_color: Optional[TensorType[3]] = None
"""Color of dataset background."""
scene_box: SceneBox = SceneBox()
"""Scene box of dataset. Used to bound the scene or provide the scene scale depending on model."""
mask_filenames: Optional[List[Path]] = None
"""Filenames for any masks that are required"""
metadata: Dict[str, Any] = to_immutable_dict({})
"""Dictionary of any metadata that be required for the given experiment.
Will be processed by the InputDataset to create any additional tensors that may be required.
"""
dataparser_transform: TensorType[3, 4] = torch.eye(4)[:3, :]
"""Transform applied by the dataparser."""
dataparser_scale: float = 1.0
"""Scale applied by the dataparser."""
@dataclass
class DataParser:
@abstractmethod
def _generate_dataparser_outputs(self, split: str = "train") -> DataparserOutputs:
"""Abstract method that returns the dataparser outputs for the given split.
Args:
split: Which dataset split to generate (train/test).
Returns:
DataparserOutputs containing data for the specified dataset and split
"""
Example#
Here is an example where we implement a DataParser for our Nerfstudio data format.
@dataclass
class NerfstudioDataParserConfig(DataParserConfig):
"""Nerfstudio dataset config"""
_target: Type = field(default_factory=lambda: Nerfstudio)
"""target class to instantiate"""
data: Path = Path("data/nerfstudio/poster")
"""Directory specifying location of data."""
scale_factor: float = 1.0
"""How much to scale the camera origins by."""
downscale_factor: Optional[int] = None
"""How much to downscale images. If not set, images are chosen such that the max dimension is <1600px."""
scene_scale: float = 1.0
"""How much to scale the region of interest by."""
orientation_method: Literal["pca", "up", "vertical", "none"] = "up"
"""The method to use for orientation."""
center_method: Literal["poses", "focus", "none"] = "poses"
"""The method to use to center the poses."""
auto_scale_poses: bool = True
"""Whether to automatically scale the poses to fit in +/- 1 bounding box."""
train_split_fraction: float = 0.9
"""The fraction of images to use for training. The remaining images are for eval."""
depth_unit_scale_factor: float = 1e-3
"""Scales the depth values to meters. Default value is 0.001 for a millimeter to meter conversion."""
@dataclass
class Nerfstudio(DataParser):
"""Nerfstudio DatasetParser"""
config: NerfstudioDataParserConfig
def _generate_dataparser_outputs(self, split="train"):
meta = load_from_json(self.config.data / "transforms.json")
image_filenames = []
poses = []
...
dataparser_outputs = DataparserOutputs(
image_filenames=image_filenames,
cameras=cameras,
scene_box=scene_box,
)
return dataparser_outputs
Train and Eval Logic#
The DataParser will generate a train and eval DataparserOutputs depending on the split argument. For example, here is how you’d initialize some InputDataset classes that live in the DataManager. Because our DataparserOutputs maintain a common form, our Datasets should be plug-and-play. These datasets will load images needed to supervise the model with RayGT objects.
config = NerfstudioDataParserConfig()
dataparser = config.setup()
# train dataparser
dataparser_outputs = dataparser.get_dataparser_outputs(split="train")
input_dataset = InputDataset(dataparser_outputs)
You can also pull out information from the DataParserOutputs for other DataManager components, such as the RayGenerator. The RayGenerator generates RayBundle objects from camera and pixel indices.
ray_generator = RayGenerator(dataparser_outputs.cameras)