Instant-NGP#
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
Running the Model#
Instant-NGP is built locally into Nerfstudio. To use the method, run
ns-train instant-ngp --help
Many of the main contributions of Instant-NGP are built into our Nerfacto method, so for real-world scenes, we recommend using the Nerfacto model.
Method#
Overview#
Instant-NGP breaks NeRF training into 3 pillars and proposes improvements to each to enable real-time training of NeRFs. The 3 pillars are:
An improved training and rendering algorithm via a ray marching scheme which uses an occupancy grid
A smaller, fully-fused neural network
An effective multi-resolution hash encoding, the main contribution of this paper.
The core idea behind the improved sampling technique is that sampling over empty space should be skipped and sampling behind high density areas should also be skipped. This is achieved by maintaining a set of multiscale occupancy grids which coarsely mark empty and non-empty space. Occupancy is stored as a single bit, and a sample on a ray is skipped if its occupancy is too low. These occupancy grids are stored independently of the trainable encoding and are updated throughout training based on the updated density predictions. The authors find they can increase sampling speed by 10-100x compared to naive approaches.
Nerfstudio uses NerfAcc as the sampling algorithm implementation. The details on NerfAcc’s sampling and occupancy grid is discussed here.
Another major bottleneck for NeRF’s training speed has been querying the neural network. The authors of this work implement the network such that it runs entirely on a single CUDA kernel. The network is also shrunk down to be just 4 layers with 64 neurons in each layer. They show that their fully-fused neural network is 5-10x faster than a Tensorflow implementation.
Nerfstudio uses the tinycudann framework to utilize the fully-fused neural networks.
The speedups at each level are multiplicative. With all their improvements, Instant-NGP reaches speedups of 1000x, which enable training NeRF scenes in a matter of seconds!
Multi-Resolution Hash Encoding#
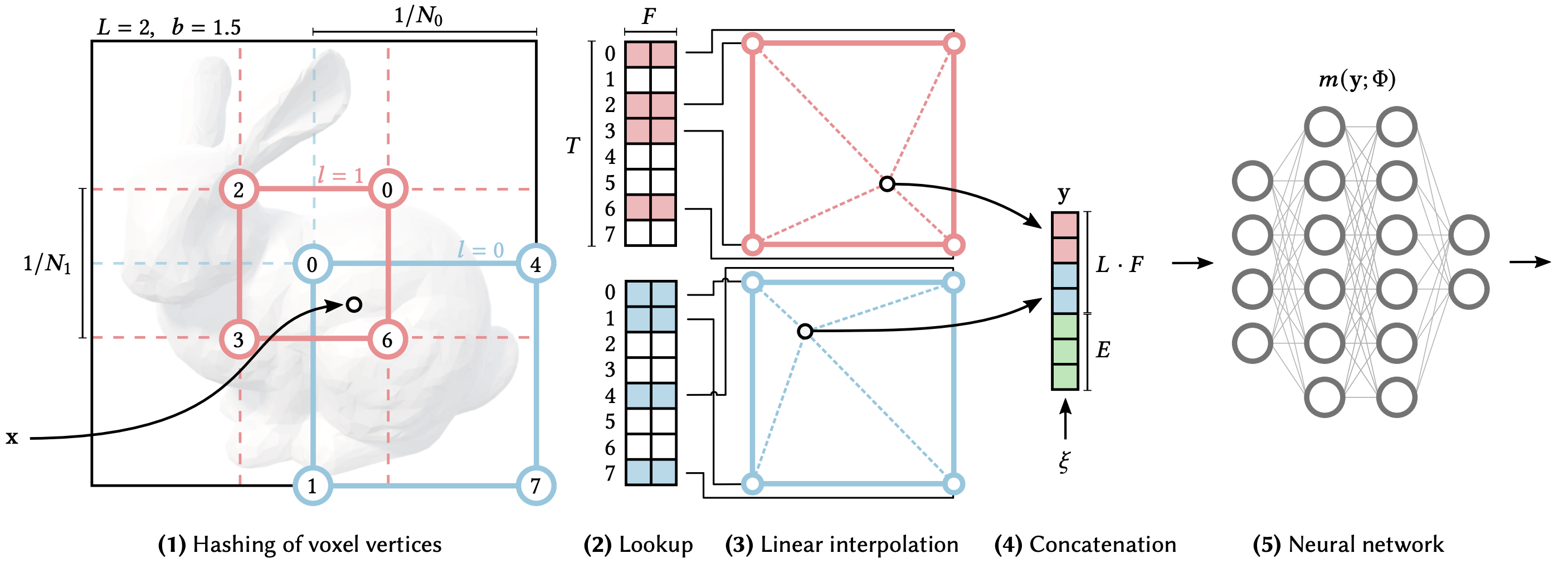
One contribution of Instant-NGP is the multi-resolution hash encoding. In the traditional NeRF pipelines, input coordinates are mapped to a higher dimensional space using a positional encoding function, which is described here. Instant-NGP proposes a trainable hash-based encoding. The idea is to map coordinates to trainable feature vectors which can be optimized in the standard flow of NeRF training.
The trainable features are F-dimensional vectors and are arranged into L grids which contain up to T vectors, where L represents the number of resolutions for features and T represents the number of feature vectors in each hash grid. The steps for the hash grid encoding, as shown in the figure provided by the authors, are as follows:
Given an input coordinate, find the surrounding voxels at L resolution levels and hash the vertices of these grids.
The hashed vertices are used as keys to look up trainable F-dimensional feature vectors.
Based on where the coordinate lies in space, the feature vectors are linearly interpolated to match the input coordinate.
The feature vectors from each grid are concatenated, along with any other parameters such as viewing direction,
The final vector is inputted into the neural network to predict the RGB and density output.
Steps 1-3 are done independently at each resolution level. Thus, since these feature vectors are trainable, when backpropagating the loss gradient, the gradients will flow through the neural network and interpolation function all the way back to the feature vectors. The feature vectors are interpolated relative to the coordinate such that the network can learn a smooth function.
An important note is that hash collisions are not explicitly handled. At each hash index, there may be multiple vertices which index to that feature vector, but because these vectors are trainable, the vertices that are most important to the specific output will have the highest gradient, and therefore automatically dominate the optimization of that feature.
This encoding structure creates a tradeoff between quality, memory, and performance. The main parameters which can be adjusted are the size of the hash table (T), the size of the feature vectors (F), and the number of resolutions (L).
Instant-NGP encodes the viewing direction using spherical harmonic encodings.
Our nerfacto model uses both the fully-fused MLP and the hash encoder, which were inspired by Instant-NGP. Lastly, our implementation covers the major ideas from Instant-NGP, but it doesn’t strictly follow every detail. Some known differences include learning rate schedulers, hyper-parameters for sampling, and how camera gradients are calculated if enabled.