Nerfacto#
Our *defacto* method.
Running the Method#
ns-train nerfacto --help
We provide a few additional variants:
Method |
Description |
Memory |
Speed |
|---|---|---|---|
|
Default Model |
~6GB |
Fast |
|
Larger higher quality |
~12GB |
Slower |
|
Even larger and higher quality |
~24GB |
Slowest |
|
Supervise on depth |
~6GB |
Fast |
Method#
Overview#
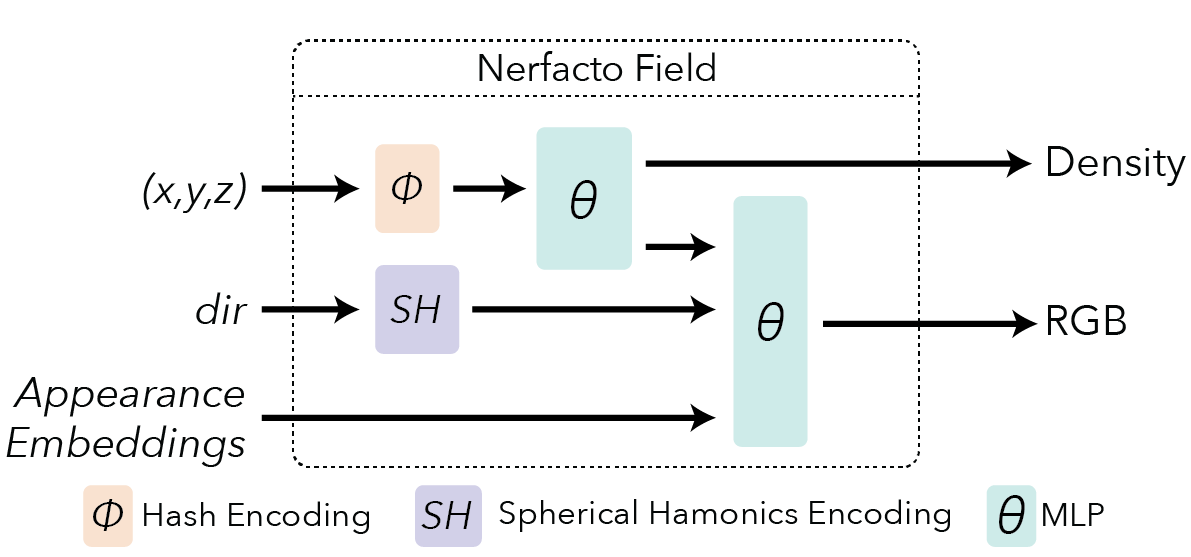
We created the nerfacto model to act as our default for real data captures of static scenes. The model is not existing published work, but rather a combination of many published methods that we have found work well for real data. This guide discusses the details of the model, understanding the NeRF model is a prerequisite.
TLDR
We combine the following techniques in this model:
Camera pose refinement
Per image appearance conditioning
Proposal sampling
Scene contraction
Hash encoding
Warning
🏗️ This guide is under construction 🏗️
Pipeline#
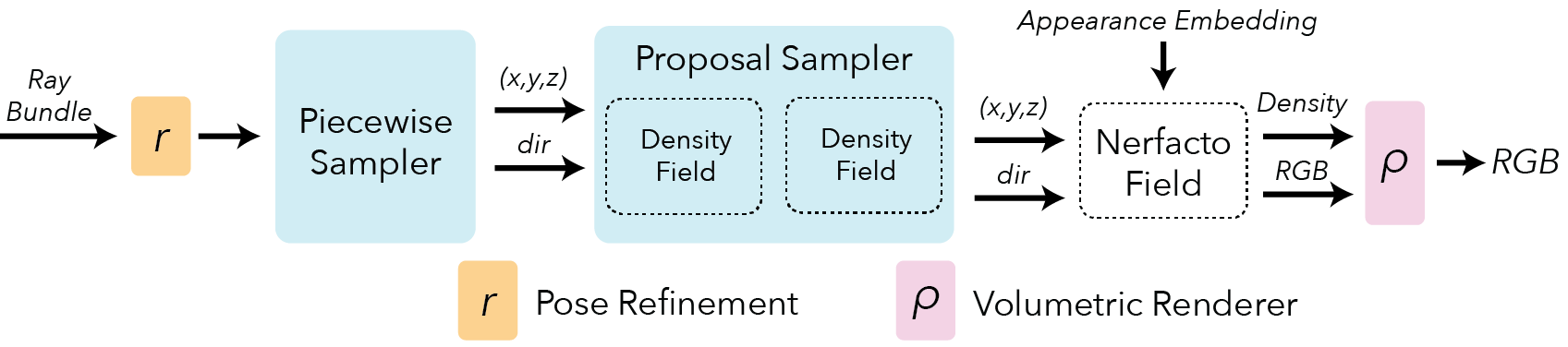
Here is an overview pipeline for nerfacto, we will walk through each component in this guide.
Pose Refinement#
It is not uncommon to have errors in the predicted camera poses. This is even more of a factor when using poses acquired from devices such as phones (ie. if you use the Record3D IOS app to capture data). Misaligned poses result in both cloudy artifacts in the scene and a reduction of sharpness and details. The NeRF framework allows us to backpropagate loss gradients to the input pose calculations. We can use this information to optimize and refine the poses.
Piecewise Sampler#
We use a Piecewise sampler to produce the initial set of samples of the scene. This sampler allocates half of the samples uniformly up to a distance of 1 from the camera. The remaining samples are distributed such that the step size increases with each sample. The step size is chosen such that the frustums are scaled versions of themselves. By increasing the step sizes, we are able to sample distant objects while still having a dense set of samples for nearby objects.
Proposal Sampler#
The proposal sampler consolidates the sample locations to the regions of the scene that contribute most to the final render (typically the first surface intersection). This greatly improves reconstruction quality. The proposal network sampler requires a density function for the scene. The density function can be implemented in a variety of ways, we find that using a small fused-mlp with a hash encoding has sufficient accuracy and is fast. The proposal network sampler can be chained together with multiple density functions to further consolidate the sampling. We have found that two density functions are better than one. Larger than 2 leads to diminishing returns.
Density Field#
The density field only needs to represent a coarse density representation of the scene to guide sampling. Combining a hash encoding with a small fused MLP (from tiny-cuda-nn) provides a fast way to query the scene. We can make it more efficient by decreasing the encoding dictionary size and number of feature levels. These simplifications have little impact on the reconstruction quality because the density function does not need to learn high frequency details during the initial passes.
Nerfacto Field#