Pipelines#
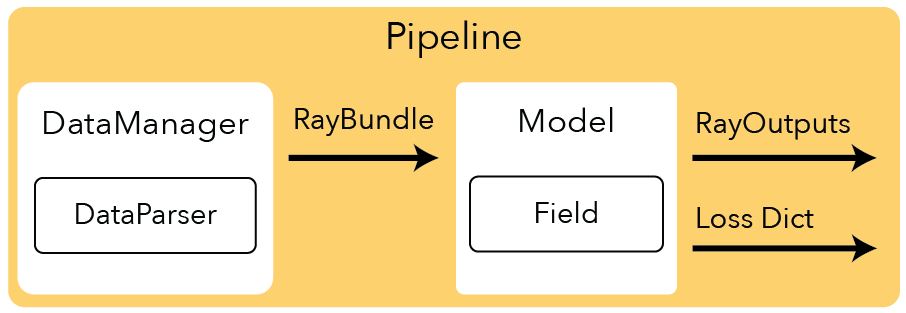
What is a Pipeline?#
The Pipeline contains all the code you need to implement a NeRF method. There are two main functions that you need to implement for the Pipeline.
class Pipeline(nn.Module):
datamanager: DataManager
model: Model
@profiler.time_function
def get_train_loss_dict(self, step: int):
"""This function gets your training loss dict. This will be responsible for
getting the next batch of data from the DataManager and interfacing with the
Model class, feeding the data to the model's forward function.
Args:
step: current iteration step to update sampler if using DDP (distributed)
"""
@profiler.time_function
def get_eval_loss_dict(self, step: int):
"""This function gets your evaluation loss dict. It needs to get the data
from the DataManager and feed it to the model's forward function
Args:
step: current iteration step
"""
Vanilla Implementation#
Here you can see a simple implementation of the get_train_loss_dict from the VanillaPipeline. Essentially, all the pipeline has to do is route data from the DataManager to the Model.
@profiler.time_function
def get_train_loss_dict(self, step: int):
ray_bundle, batch = self.datamanager.next_train(step)
model_outputs = self.model(ray_bundle)
metrics_dict = self.model.get_metrics_dict(model_outputs, batch)
loss_dict = self.model.get_loss_dict(model_outputs, batch, metrics_dict)
return model_outputs, loss_dict, metrics_dict
Creating Custom Methods#
Note
The VanillaPipeline works for most of our methods.
We also have a DynamicBatchPipeline that is used with InstantNGP to dynamically choose the number of rays to use per training and evaluation iteration.